 Tweet
Tweet
Introduction aux systèmes d'exploitation - Chapitre 2 : Les processus
2.1 Modèle
2.1.1 Notion de processus
Modèle simple de représentation de lexécution de tâches au sein dun OS.
Un processus est une instance dun programme en train de sexécuter.
Un processus modélise lexécution dun programme sur un processeur virtuel disposant de :
- Un compteur ordinal > Il pointe sur linstruction à exécuter
- Un jeu de registres
- De mémoire virtuelle
Le processeur physique commute entre les processus sous lordre dun ordonnanceur.
Dans un système à temps partagé, tous les processus sexécutent en même temps mais un seul à la fois.
Si les même opérations étaient lancées deux fois de suite, le temps dexécution ne serait pas forcément le même dû :
- Au positionnement des têtes du HDD
- À loccupation des caches
- Au traitement des évènements asynchrones qui peuvent conduire à des ordonnancements très différents
On ne peut donc pas faire dhypothèses sur le facteur temps > Gestion plus compliquées des interruptions au point de vue matériel.
2.1.2 Relations entre les processus
Un processus est créé par un autre processus via un appel système. On peut donc définir (selon l OS) une arborescence de processus à partir dun ancêtre commun (init sur Unix).
Les processus nont pas darborescence dans un système windows.
On peut donc créer des groupes de processus qui seront un fait une sous partie de larborescence de base. > On peut contrôler plus finement les commandes sur les processus.
2.1.3 Etats dun processus
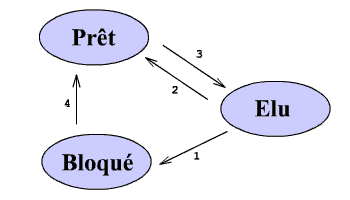
Elu : En cours dexécution sur le processeur. Machine multi-processus > Plusieurs élus en même temps (au plus autant délus que de processeurs).
Prêt : Processus auquel il ne manque que la ressource processeur.
Bloqué : Il est en attente dun processus externe (I/O, frappe clavier, )
Le 2 nexiste pas dans un système de traitement par lots
2. Le processus a épuisé le temps qui lui était accordé et lordonnanceur (appelé de façon asynchrone par interruption) élit un autre processus.
3. Lordonnanceur passe un processus en élu en choisissant dans les processus prêts.
1. Le processus sendort en attente dun évènement externe > lordonnanceur est appelé ( de manière explicite par le processus) élit un autre processus.
4. Lévènement attendu par le processus se produit (cest lOS qui gère sont traitement vu que le processus est endormi). LOS interrompt donc temporairement le processus en exécution pour gérer lévènement et passer le processus de bloqué à prêt.
Lexécution dun processus peut donc progresser de deux manières :
- Synchrone : le processus est élu et dispose de la ressource processeur.
- Asynchrone : le processus est élu mais est arrêté par lOS pour finir une I/O
2.2 Mise en oeuvre
Les interruptions et la gestion des processus forment toujours la gestion la plus basse de lOS afin de faire abstraction de ces problèmes pour les couches supérieures.
2.2.1 Gestion des processus
Pour mettre en oeuvre la gestion des processus, lOS dispose dune table des processus (jamais swapée) dont chaque entrée contient des informations sur un processus particulier tel que :
- Les valeurs de son compteur ordinal, de sont pointeur de pile et des autres registres processeur
- Son numéro de processus, son état sa priorité
- Son occupation mémoire
- Sa liste des fichiers ouverts
Pour éviter que cette table ne prenne trop de place, elle est découpée en 2 parties.
- La première (jamais swapée) contient les informations indispensables pour entamer le chargement dun processus.
- La seconde (swappable car dans lespace mémoire propre du processus) contient les informations nécessaire lors du passage de prêt à élu.
2.2.2 Gestion des interruptions
Lorsque le système reçoit une interruption, il localise la routine de traitement de celle-ci en la localisant dans un tableau indexé sur son type.
L'interruption logicielle est donc une interruption classique en langage machine et non une interruption provenant dun autre composant.
Les étapes de traitement dune interruption sont :
1. Le processeur sauvegarde la valeur de son compteur ordinal dans la pile courante, détermine le type dinterruption , passe en mode noyau et charge la nouvelle valeur de son compteur ordinal (ladresse de la routine de traitement de linterruption).
2. La routine sauvegarde les registres processeur dans la pile ou en construit une nouvelle puis appelle la routine de gestion de gestion de linterruption.
3. Au retour de cette appel, la routine de traitement restaure les registres processeurs et replace la valeur du compteur ordinal afin de relancer le processeur sur le bon processus
2.3 Communication inter-processus
Les processus ne sexécutent pas tous de manières isolée. Certains ont besoin de communiquer, de se synchroniser et dautres encore sont en compétition pour les ressources du système (ressources non partageables au risque de créer des inter-blocages).
Exemple : Une liste dimpression
Si deux processus veulent imprimer, ils doivent chacun recevoir un numéro dordre puis placer leur document dans la file puis incrémenter pour le numéro suivant.
Cependant, si lune des tâches est interrompue avant dincrémenter le compteur, deux processus auront le même numéro et lun deux sera perdu
Le système doit donc fournir un support sûr de la communication inter-processus, celui-ci peut être basé sur :
1. Les mécanismes du système de fichiers (pipes, pipes nommés)
2. Les mécanismes de gestion de la mémoire (mémoire partagée, sémaphores)
Le vrai problème est laccès concurrentiel à une variable partagée, et ce à cause du fait que cela peut créer des résultats incohérents de façon imprévisible.
2.4 Sections critiques
Elles ont pour but dinterdire la modification de données partagées à plus dun processus à la fois et donc définir des exclusions mutuelles sur des portions spécifiques de code appelées sections critiques.
On peut définir le comportement dans les sections critiques par :
- Deux processus ne peuvent être simultanément dans la même section critique > Suffisante pour éviter le conflits mais ne garantit pas légalité.
- Aucune hypothèse ne peut être faite sur les vitesses des processus
- Aucun processus suspendu en dehors dune section critique ne peut bloquer les autres
- Aucun processus ne doit attendre trop longtemps pour entrer en section critique
2.4.1 Masquage des interruptions
On désactive les interruptions avant dentrer en section critique et on les restaure à la fin > Pas dordonnancement.
Désavantages :
- Inéquitable : Un processus se tenant longtemps en section critique bloque les autres
- Dangereux : Si on oublie de restaurer les interruptions > Blocage complet.
- Inefficace : - Sur les systèmes multi-processeurs puisque quun processus sur le deuxième processeur peut rentrer en section critique. - Quand un processus entre en section critique il bloque tout les autres, même ceux qui ne sont pas en section critique
Elle est utilisée par lOS pour manipuler ses fonctions internes.
2.4.2 Variables de verrouillage ( équivalant à TSL )
Pour éviter de bloquer tout les autres processus, on crée une variable verrou par section critique.
Un processus voulant entrer en section critique teste donc cette variable :
Si VRAI, il attend (de manière active)
Si FAUX il entre et la positionne à VRAI et quand il sort, il la repositionne à FAUX
Désavantage :
- Uniquement pour les machines mono-processeur
- Les deux processus modifient la même variable en même temps
- Quand il a finit dattendre et avant de positionner le verrou il peut être interrompu par un autre lui « volant » sa section critique
Une solution serait dinhiber les interruptions à la sortie de lattente active et de vérifier une dernière fois si le verrou est positionné avant dentrer en section critique. Si ce nest pas le cas on entre en section critique, sinon on réactive les interruptions et on retourne dans lattente active.
2.4.3 Variable dalternance
Pour éviter de modifier la même variable en même temps, on crée une variable dalternance qui définit le numéro du processus qui peut entrer en section critique.
Désavantage :
- Quand un processus sort de section critique il sinterdit dy retourner avant que ça ne soit de nouveau son tout > Si un autre processus dure plus longtemps, on se bloque.
2.4.4 Variable dalternance de Peterson
Elle améliorer la simple variable dalternance car elle permet à un processus dont ce nest pas le tour de rentrer en section critique si les autres ne sont pas prêts.
Cette solution se base sur deux procédures entrer_region() et sortir_region() qui encadrent la section critique.
Cette solution est valable et efficace.
2.4.5 Instruction TSL
On se base sur linstruction TSL qui est une instruction en langage machine.
Cette solution est valable et efficace même sur les multi-processeurs car on bloque le bus daccès à cette case mémoire.
2.4.6 Primitives sleep et wakeup
Ce sont des appels système.
Sleep : Endort le processus qui lappelle en rendant la main à lordonnanceur
Wakeup : Réveille un processus dans lidentifiant est rentré en paramètre.
Ils peuvent dans certains cas former des inter-blocages ou des dead-locks
2.4.7 Sémaphores
On utilise une variable entière (appelée sémaphore) pour comptabiliser le nombre de réveils en attente et on encapsule cette variable dans un objet système manipulable uniquement par des appels systèmes spécifiques.
La primitive down décrémente le sémaphore et endort le processus appelant si il était déjà à 0.
La primitive up incrémente le sémaphore si aucun processus nest endormi sinon, il en réveil un au hasard.
La manipulation des sémaphores via des appels systèmes permet de désactiver de manière efficace et sûre les interruptions vu que la manipulation du sémaphore est à la charge de lOS et pas de lutilisateur.
Dans le cas dun système multi-processeur, les sémaphores sont protégés par des variables de verrouillages manipulées par linstruction TSL (ici lattente active nest pas préjudiciable car elle sera de courte durée).
Lutilisation des sémaphores simplifie les exclusions mutuelles, mais elles restent tout de même fastidieuse et peut mener à des inter-blocages (au cas où on inverserait deux down).
2.4.8 Moniteurs
Il sert à offrir le support des exclusions mutuelles au niveau du langage.
Il est composé dun ensemble de données et de procédure dont un seul processus peut être actif en même temps.
Dans ce cas, cest le compilateur qui gère les exclusions mutuelles (en ajoutant des sémaphores) > Le risque derreur est bien plus bas.
Le moniteur nécessite les instructions wait et signal pour fonctionner correctement et permettre léchange de données dans sa structure.
Wait : bloque le processus appelant sur la variable passée en paramètre.
Signal : réveil lun des processus bloqué sur la variable
Wait et signal ressemblent à sleep et wakeup mais ne permettent pas lexclusion concurrente de celles-ci.
Ils règlent donc les problèmes de sleep et de wakeup
2.4.9 Echange de messages
Le problème de ressources partagées peut être reformulé en terme de communication inter-processus. Celle-ci est implémentée via deux primitives:
Send: envoi d'un message à un processus donné
Receive: lis un message provenant dun processus donné ou quelconque. Si aucun message nest disponible, receive bloque le processus appelé.
Cette solution permet la communication sur un système à mémoire partagée mais est beaucoup plus dur à mettre en oeuvre car elle nécessite de régler ces problèmes:
- La perte possible des messages > Message de bonne réception avec des message numérotés pour éviter les doublons. Les messages récepteur > envoyeur peuvent aussi être regroupés en un seul message.
- Le nomage des processus > Ensemble de nomage global à lensemble des processus > Goulot étranglement posé par laccès à cette ressource. De plus il est impossible dempêcher deux processus de porter le même nom
- Lauthentification des messages > Crypto systèmes (clés publiques et privées) mais dans ce cas on a besoin de services externes qui risquent de créer des goulots détranglement
- Surcoût dû à la latence > Problème des intermédiaires mis en jeu, chaque intermédiaire représente une recopie mémoire
- Tolérance aux pannes > Quand la réponse ne vient pas on ne peut pas savoir si lopération sest effectuée > On peut obliger à envoyer une réponse
2.5 Problème classique de communication inter-processus
2.5.1 Le problème des philosophes
Cinq philosophes sont assis autour dune table et chacun a devant lui une assiette pleine de spaghetti tellement glissant quil faut deux fourchettes pour les manger. Une fourchette étant systématiquement déposée entre deux assiettes consécutives.
Un philosophe passe son temps à penser ou à manger. Sil obtient les feux fourchettes, il mange pendant un certain temps puis se remet à manger.
Le problème consiste à permettre à chacun des philosophes de faire chacune de ses activités sans jamais être bloqué de manière irrémédiable.
Dans ce cas pour éviter les inter blocage, on utilisera des sémaphores et des mutes (sémaphores dexclusion mutuelle).
2.6 Ordonnancement de processus
Cest un algorithme qui sélectionne lequel des processus prêt va sexécuter.
Dans un système de traitement par lots, on exécute le programme suivant dès quun emplacement se libère dans la mémoire (dès quon a finit le précédent).
Dans un cas de multi-utilisateurs, multi-tâches et multi-processeurs lordonnancement peut devenir très complexe. Il sappuie sur les critères suivants :
- Chaque processus doit pouvoir disposer du processeur
- Lutilisation du processeur doit être maximale
- On doit minimiser le temps de réponse
- On doit minimiser le temps dexécution
- On doit maximiser le nombre de travaux par unité de temps
Ces critères sont mutuellement exclusifs.
Pour assurer léquité il est nécessaire de mettre en oeuvre un mécanisme de temporisation et de rendre la main à lordonnanceur après avoir épuisé son temps dexécution (système préemptif > complexité ++) .
2.6.1 Ordonnancement circulaire
On assigne a chaque processus un quantum de temps, si dans ce quantum il se termine ou passe en état bloqué, on repasse la main à lordonnanceur. Sinon on va jusquau bout du quantum puis, on repasse à lordonnanceur.
Le principal problème ici est de fixer un bon quantum de temps, trop court > on passe plus de temps à switcher quautre chose. Trop long > Pas fluide
2.6.2 Ordonnancement avec priorité
On souhaite favoriser certaines tâches en leur attribuant une priorité plus élevée (les priorités changent dynamiquement).
Par exemple, certains processus passent la majeur partie de leur temps en état bloqué, il est donc préférable de leur donner une préférence haute afin de les « lancer » dans leurs travail sans attendre.
Les processus sont aussi regroupés en classe de priorité. Cela permet de faire de lordonnancement par priorité entre les classes et circulaire dans une même classe (dans les faits, les ordonnancements sont souvent hybrides).
Le problème majeure est de changer la classe de priorité dun processus. Un processus qui a calculé longtemps avant de redevenir interactif aura donc une priorité très haute (car pendant son calcul elle était beaucoup plus faible).
2.6.3 Ordonnancement du plus court dabord
Ce type dordonnancement se fait sur une série de tâche dont on peut savoir la durée à lavance.
Si la file dattente contient plusieurs tâches de même priorité, on minimise le temps dexécution en effectuant toujours dabord celle qui à le temps le plus court.
Cette technique peut être adaptée à des processus interactifs si lon considère que chaque commande utilisateur est un processus indépendant. Si lon ne connait pas la durée dune tâche, on peut alors spéculer par rapport à la durée des tâches précédents.
2.6.4 Ordonnancement dicté par une politique
Le but de cet ordonnancement est de garantir à lutilisateur un temps de réponse maximum annoncé (par exemple). Dans un tel cas, le système retient le temps processeur utilisé par chaque utilisateur et le divise par le nombre dutilisateurs connecté afin de choisir le rapport le plus petit.
Utilisé principalement pour les systèmes en temps réel > Les usines par exemple (chaine de production)
2.6.5 Ordonnancement à deux niveaux
Jusquici on a supposé que tout les processus étaient en mémoire centrale dès le début. Dans les faits ce nest pas forcément le cas.
Si le processus est swappé, le temps daccès sera plusieurs fois plus long et cette latence doit être prise en compte par lalgorithme dordonnancement.
On utilise donc un ordonnanceur à deux niveaux :
- Ordonnanceur habituel (bas niveaux)
- Ordonnanceur haut niveau appelé de temps en temps qui échange les processus entre le disque et la mémoire centrale.
Pour décider de la migration lordonnanceur haut niveau se base sur :
- Le temps écoulé depuis le dernier va et vient
- La quantité de temps processeur déjà utilisée par le processus
- La taille du processus (déplacer un petit est moins couteux)
- La priorité du processus
Sous Unix :
Lordonnanceur de haut niveau est le swapper qui sexécute en mode noyau (pour ne pas devoir passer par des appels systèmes).
Si la swapper doit migrer un processus sur le disque (manque de place en mémoire), il choisit un processus non zombie (car ils ne consomment pas de place en mémoire) et non verrouillés. Donc les processus endormis sont choisi en priorité.
